Introduction
Today’s business is operating in an increasingly competitive environment which is interdependent on an intense focus on changing customer preferences, enhanced productivity and improved quality to sustain organizational growth and profitability. In order to remain competitive it has become imperative for the company to improve the productivity of not only the individuals but also of the performance of the organization as a whole. This calls for drastic reduction in costs, wider use of technology for automation, use of improved information and technology systems, improved data access and higher level of quality in customer service. Computer and web technology has been identified as one of the important enablers for improving efficiency in all these areas.
Until the early 1980s Information Systems technology, mostly, was based on very powerful Mainframes and Terminals with poor capabilities. Mainframes store data and perform all necessary activities and terminals are used only to display the results of the mainframe processes. The most significant limitations of this technology are that it does not easily support graphical user interfaces and access to multiple databases.
Multi-Tier Systems – a Background
Introduction of Personal Computers (PCs), with independent process capabilities, made it possible to share activity between very powerful server and less powerful, but still independent computers (desktops). Servers and desktops (PCs) where assembled into networks and, originally, where based on File Sharing architectures. Using this technology, server downloads files from shared location to desktop environment, in which logic meets the data and performs the requested functionality. Though this technology separates data from logic, it still had significant limitation in serving a very small number of users numbering at the maximum 12. It was a cumbersome exercise to transfer the whole file instead of partial and relevant data involving much time and efforts than actually needed to perform specific tasks.
In order to resolve the limitations of the file sharing architecture, relational database servers were developed to replace the file-sharing servers, making possible the Client-Server architecture to hit the road. The Client-Server architecture resulted in providing significant advantages in reducing the network traffic. This development provided a query mechanism with the purpose of fetching and saving only relevant data, rather than transferring the total file, improved multi update of the stored data and standardized the remote procedures calls, typically, using statements of Standard Query Language (SQL) in order to communicate between client and database server.
Since then, the term Client-Server architecture widely emerged into computer science lexicon. Specialists have being developing different architectures based on the Client-Server concepts. The main advantages that architectures try to achieve are usability, scalability, flexibility, maintainability, reusability, security, fault tolerance, complexity and performance of course. These distinct features of latest architectures are dealt with, in later chapters. It was possible to solve many complex problems by dividing them into sub-problems, so complex Information Systems or Applications could be sliced, like loaf of bread, into separate logical or physical parts in order to achieve the advantages mentioned above. Those slices or parts conventionally are called layers and tiers.
Need for Multi-tier Architecture
Designing a business information architecture for exploiting diverse databases and information systems has been found to be rather complicated than designing a basic data warehouse catering to a single application. In general, the information management system in any organization is expected to lend support to solving complex issues in business environments where the objectives may not be well defined or they may present themselves surprisingly.
This implies that information management system must operate in an environment where the business direction is completely open-ended. This has necessitated the system implementation to manage information input pouring in from various sources. Such information need to be organized in such a way that multiple users can view the required contents. It should also allow the users to exploit the database to devise their own information contents.
In order to function in such a complex business environment the information management system is expected to empower the business analyst to have access to useful, filtered data and information extracted and organized from many available data archives. It is this filtering resource, which acts more specifically in supporting the problem solving activities of a progressive organization and it is the central focus on the development of multi-tier architecture for complex business applications.
Another aspect of business strategies is that they involve creative processes, which are often found to be abstract and therefore there will be no means of defining or quantifying them. This also makes the assessing the requirements complex and designing the information management processes challenging. In fact, this complexity and challenges were at the root of the development of the iterative and flexible development approach by engaging multi-tiers. It has been found that multi-tier information management architecture is capable of providing increase flexibility that enables more controllability and growth.
Taking into account the complex business requirements, the design for information management architectures typically make use of a multi-tiered approach. As observed earlier the Client-Server architecture is based on a two or three tier approach. The client/server or client/middleware/server format characterizes this approach. It is possible to use any number of tiers for the creation of an efficient information management system. The number of tiers largely depends on data structure and the distribution of the data sources. The number of application servers also determines the number of tiers. “This approach allows for the creation of multiple levels of entry and provides added flexibility to create division work areas and special work groups” (Horsburg.com, 2000)
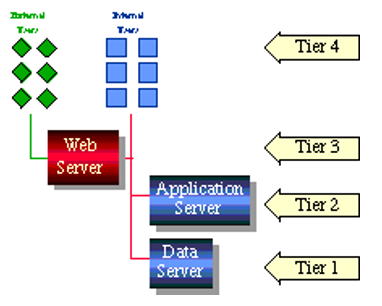
The diagram illustrates the basic architecture of a multi-tier system that make use of the Web server as a tier that functions as separator between the external and internal users of the system thus giving more access availability to the multi-users and system-control for the in-house users.
Within the context of multi-tier information management system, this paper will examine the evolution and adoption of the multi-tier information processing systems along with various business applications of the technology. The pros and cons of different architecture will also be analyzed in detail.
Aims and Objectives
The broad aim of this paper is to examine and report on the multi-tier information management systems, as they currently exist in various spheres of business applications. For achieving this aim, the research will extend to the study of the evolution and adoption of the multi-tier information management system, application of the system to meet varied business applications and domains, pros and cons of different architecture created using the multi-tier technology and a comparative analysis of layers and tiers.
In order to make the presentation cohesive this paper is structured to have different chapters. While chapter one introduces the topic of study, it also spells out the aims and objectives of the research. Chapter two will present a detailed review of the related literature to enhance the knowledge of the reader on the subject matter of study. A brief description of the methodology is presented in chapter three followed by case studies of multi-tier applications in retail and finance systems in chapter four, which is titled findings and analysis. Chapter five is the concluding one presenting a recap of various issues discussed in the text of the paper and the chapter makes few recommendations for further research.
Review of Related Literature
Any management is inseparably dependent on information management systems to facilitate the process of business decision-making. Many of the administrative, business and organizational practices in large and medium sized companies use management information systems extensively. For instance in the area of marketing development and use of management information system based on a large customer database is of prime importance to support the processes of product positioning, marketing, sales and after sales customer services.
Therefore, development of information management systems that support organizational processes and innovative business application models are of the need of the hour to sustain the sales and profitability growth. There are no standardized technologies in the real world situations, which are capable of integrating multiple systems and applications. Nevertheless, powerful, open and generic technologies have been developed over the period, which serve the integration needs of business application models. One of such technologies developed is the multi-tier information management system, which is being analyzed in this chapter with respect to its evolution and adaptation.
Introduction
With the advent and growth of internet and the maturity achieved in corporate infrastructure there has been a growing demand for instant access to multifarious information by customers as well as higher echelons of management of different organizations. The data and information required varies from accessing the online catalogue, placing an order online, retrieving account information or sending and receiving emails and all of this immediate response.
This has put a great pressure on the information and communication technology departments of companies to design new networks and systems so that a large number of people can access corporate resources at the same time for various purposes. In order to meet this unceasing demand technologists focused on technology architecture model to store the information that can be accessed and delivered to the clients. Soon it developed into the use of two-tier Client/Server architecture. In this model, “desktop software called clients request information over the corporate network infrastructure to servers running software that fulfilled a client’s request”.
However, this two-tier architecture had limitations of keeping client software updated. This model posed difficulty in maintaining an also proved expensive especially in large corporate setups where there are a number of intranets and a large number of remote users.
This necessitated the development of three-tier or multi-tier architecture to cope with the volume of data and changed requirements. Web-based three-tier and multi-tier architecture do not require the upgrading of the client software with changes in presentation and functionality of an application. However, the advancement to multi-tier technology required the revamping of the infrastructure with the abandonment of two-tier architecture and the building of new multi-tier architecture. This chapter presents a review of the available literature on multi-tier architecture.
Evolution of Multi-tier Architecture
Evolution of multi-tier architecture followed the same course as the development of programming languages and took shape over decades. The key objective of multi-tier architecture of sharing the resources among clients can be compared with the fundamental design philosophy of developing programs. Traditionally programmers used assembly language to write programs. These programs worked on the concept of software services, which were shared with the program running on the machine. Use of software services suffered a drawback in which the assembly language subroutines were machine specific and could not serve different machines.
This led to the development of FORTRAN and COBOL. Programs written in FORTRAN had the capability of sharing functionality by using functions instead of assembly language subroutines. It was the case with COBOL. Here there was the advantage with the functions running on different machines when the function was recompiled. However, programs and functions had to confine to specific machines. Data exchange was not possible at that point of time, when magnetic tapes were used to transfer data, programs, and software services from one machine to another. The real-time transmission was not in practice.
Real-time transmission came into being with the introduction of UNIX operating system. “The UNIX operating system contains support for Transmission Control Protocol/Internet Protocol (TCP/IP), which is a standard that specifies how to create, translate, and control transmissions between machines over a computer network”. Around the same time, Remote Procedure Call (RPC), which enables the sharing of functions written in any procedural language such as FORTRAN, COBOL, and C programming language?
This broke the barrier of residing with the same machine as it was made possible for a programmer to call a function that was created by a different program, using a different procedural language residing in a different machine so long as both the machines are connected to the same network. Another important milestone in the development of distributive system is the eXternal Data Representation (XDR). Further development of XDR enabled the exchange of complex data structures among programs and software services. This removed the hurdle of limiting an application to one machine by making the applications collaborative development efforts that could utilize software services available throughout the network.
Subsequent evolutionary step took place with the development of object-oriented languages such as C++ and Java. “Procedural languages focused on functionality, where a program was organized into functions that contained statements and data that were necessary to execute a task.” Functions contain internal software services within a program or external software services known as RPC. On the other hand, programs written in an object-oriented language consist of software objects and they are not organized by functionality.
Subsequent protocols like Common Object Request Broker Architecture (CORBA) and Distributed Common Object Model (DCOM) developed to access software objects were incompatible with each other. Finally, the introduction of Hypertext Transport Protocol (HTTP) by internet, which is used to share information between machines, resolved the conflict between the competing protocols developed earlier. HTTP, which is a high-level protocol does not replace TCP/IP, but uses TCP/IP in low-level transmissions.
Web services are the next evolution of software services. “Web services” does not have relevance to the term “web” as applied to internet. “Web services are a web of services where services are software building blocks that are available on a network from which programmers can efficiently create large-scale distributive systems.” A number of web services are used in a typical large-scale distributive system. Each web service is associated with a tier in the multi-tier architecture, which is used to share the resources over the infrastructure of any large organization.
The Tier
Information Systems are divided into different tiers. Tiers can be physical and logical. Physical tier means separation of the system’s parts into different computers. For example, a system can be divided into client and server machines – client runs the user interface (UI) client and server holds the database. Logical tier means organization of different system’s components on the same machine. The logical tier is also called a layer. Tiers refer to machines, processes and networks against layers, which ascribe to internal process, code or modules organization. Accordingly, layers can be located in one or more tiers.
Layers
“A layer is a group of classes that have the same set of link-time module dependencies to other modules. In other words, a layer is a group of reusable components that are reusable in similar circumstances“(Wikipedia, n.d.). Layers are abstractions, which are determined by the purpose and logical modularity of an Information System. Layers that are planned to be used by other layers should expose Application Program Interface (API), which makes it possible for others to communicate that layers and use their functionality.
Well-planned layers make the system maintainable and extensible usually without any performance hits. For example, a given system contains a Data Access Layer (DAL), the role of is to fetch data from a database and output it in defined format (like XML) to the higher layer. Now, let us imagine that the existing data source has to be replaced with another. In this scenario, all one has to do is to suit the DAL code to be able working with the new data source without any impact on the higher layers. In other words – only the inner logic of a single logical layer will be changed; but other logical parts of the system will remain as they are. It is very important to keep the APIs stable in order to avoid chain reaction of the changes on other parts of the system.
Nevertheless, there is a risk for over-architecting or very strong dependencies between the layers that can cause for undesired affects, which were best described by David Hayden in his article “Web Applications: N-Tier vs. N-Layer” (Hayden, 2005 ): ”
- Rigidity – System is hard to change in even the simplest ways.
- Fragility – Changes cause system to break easily and require other changes.
- Immobility – Difficult to entangle components that can be reused in other systems
- Viscosity – doing things, right is harder than doing things wrong.
- Needless Complexity – System contains infrastructure that has no direct benefit.
- Needless Repetition – Repeated structures that should have a single abstraction
- Opacity – Code is hard to understand.“
Layers can be designed according to different methodologies, the most known of them are Object Oriented Design (OOD) and Service Oriented Architecture (SOA). Because of the logical abstraction, it is very difficult to nominate all possible layers, but there are still some common layers, which can be used by a typical Information System.
The most common layers used in Information System are:
Presentation Layer
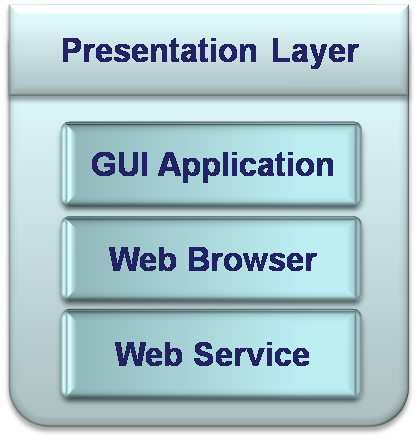
This is an entry point to the Information System from which users can operate the Information System. This layer is responsible for acquiring information from the user and rendering data to the user. There some additional tasks that Presentation layer does, like: performing data validations and simple calculations, defining styling, organizing displayed information and more. In some architectures Presentation layer can have also an orchestration role by routing the clients’ requests to different data sources.
“This layer comprises the entire user experience. Not only does this layer provide a graphical user interface (GUI) so that users can interact with the application, input data, and view the results of requests, it also manages the manipulation and formatting of data once the client receives it back from the server.” (Microsoft Corporation, 2008). This layer is represented by:
- Client program (UI – user interface) it is an application, which is specially created to operate only a specific Information System. The Client can be a simple Console application or very reach graphic multi window program.
- Web browser – it is a standard application, which can serve different Information Systems, assuming that the information, which should be displayed by the browser, is appropriately formatted. For example – browsers can display HTML data, so the system has to invert the raw data into HTML.
- Web Services – it is a service, which exposed by the Information System in a standard format (WSDL – Web Services Definition/Description Language). Instead of a Client (UI) application, there are some external systems, which operate the Information System using the Web services they expose. A good example for that could be data supply companies, like news suppliers. They offer for a price access to their Web Services with news information. Customers can use that information in their own systems as desired.
Application Logic Layer
Application layer, usually, has a role of a system engine. Its minimal functionality is to communicate between the Presentation and Resource layers. This is very poor functionality, which is, usually, presented in small and not distributed systems with application logic implemented in Resource layer (to be discussed later). However, in large modern Information systems, this layer has very reach and complex functionalities like communication channel, running of business logic algorithms, dealing with performance and security issues, routing between different system parts and other systems and more.
Actually, the term “Application Layer” is very abstractive and it is much more meaningful to discuss about its components rather than about itself. Application layer comprises several sub-layers with very specific functionality. These layers have various names and definitions, usually according to software platforms and environments they run in. There are some possible application sub-layers, which have been implemented in some real Information systems:
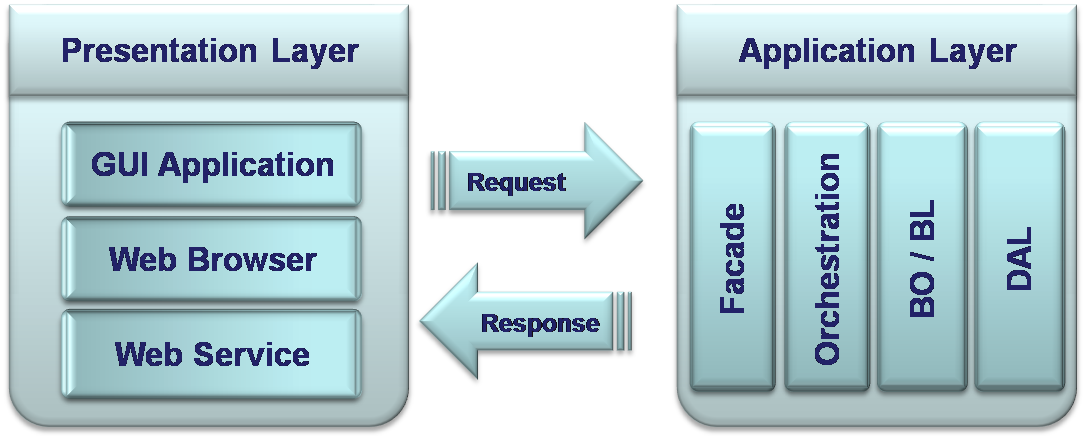
Facade
It is an entry point, which makes it possible for Presentation layer to communicate with the Application layer. As an example, it can be (not necessarily) implemented by Web server, which can process requests from the Presentation layer and response back with the information that the application logic reproduced.
Orchestration
This layer activated directly by the Façade and has a role of router in distributed systems (see Tiers below) that decides which of the deeper layers is going to be activated in order to process the incoming request.
BLL / BL / BO
This layer has many names, like BO – Business Object or BLL/BL /BLR–Business Layer, which describe the same meaning. This layer represents the business logic of the Information system, implementing logical algorithms and rules. Its components take manipulates data, which coming from opposite edges of the system – user and data resource. Functionality of this layer achieves, among other things, very important purpose – separation between data or information and logic.
DAL
DAL – Data Access Layer implements functionality for interaction with Resource Management Layer or in most of the modern Information systems with relational Databases. Actually, this layer is a kind of abstraction above the system’s Database. It exempts the logic of the Application layer from Data base issues, like Data base type, connections.
Resource Management Layer
This layer stores the raw data and contains some kind of management system to manipulate this data. In modern systems, a relational Database and its Relational Data Base Management System (RDBMS) represent this layer. Relational Database stores data in the form of related tables and RDBMS supplies Standard Query Language (SQL) for Data base administration and data manipulations. The Data Access Layer uses the Database API to execute direct SQL queries or some more complex DB objects to retrieve or save.
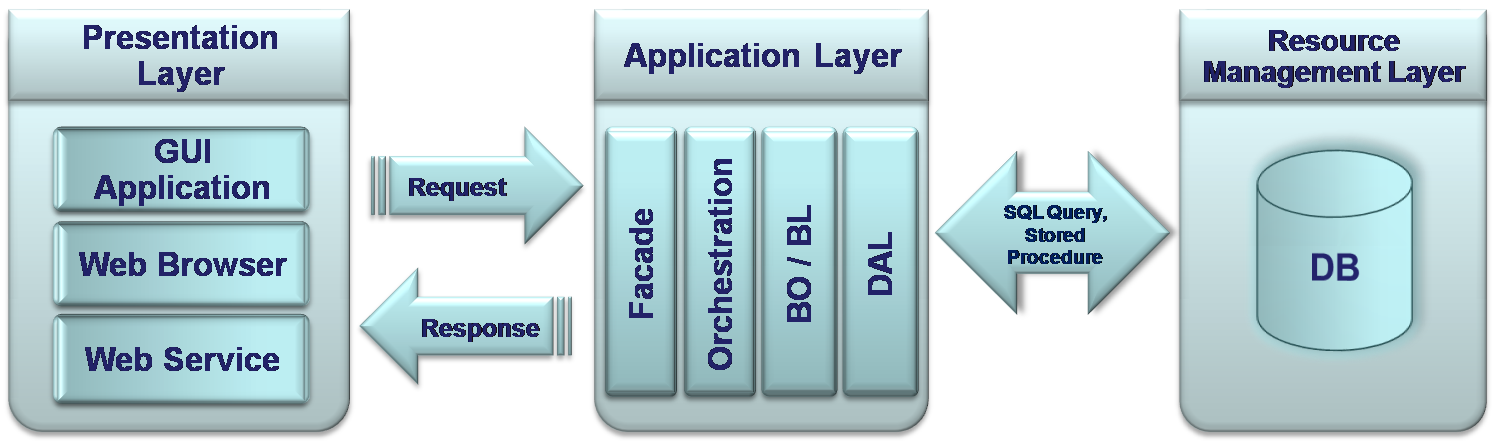
Layers can be organized and distributed in different ways. Generally, it happens while organizing sub-layers of an Application layer into independent machines, or distributed tiers, as otherwise called.
Single-Tier: Fully centralized systems
All the Information System’s components/layers are located in a single machine. This is a typical architecture of Mainframe systems, while the system is fully centralized. Users use the Information system through “Dumb Terminals”, which can only display the information, but what is displayed and how it appears is fully controlled by the server.
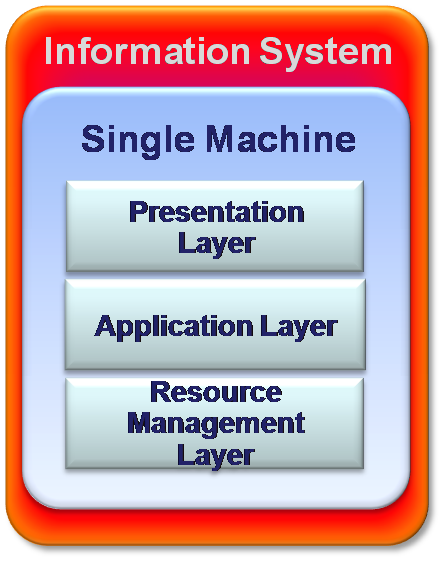
There are several advantages of single tier architecture. This type of system provides maximum performance and there is no need for development of programs at the client. There is also no need of maintenance and deployment. Similarly, this system does not require any interfaces between layers and client programs. The single layer architecture enjoys highest reliability and error recovery. There is no need for context switching which is a distinct advantage of this system.
However, there are several disadvantages associated with the system. The system involves high hardware cost. Since the server runs the whole system and serves many current users, there is the need for strong computer, which entails heavy cost. Graphic user interfaces are very pure and it is very difficult to divide the server into different modules. The scalability in this case is very low as compared to multi-tier architecture, as it can accommodate only twelve users at the maximum.
Two-Tier: Server centralized – simple Client-Server systems
As personal computers appeared and became powerful machines in the 1980s, it made it possible for IT designers to move the Presentation layer of an Information system to the user’s PC. The user’s computer called Client. The Application layer (if any) and the Resource Management layer located on another powerful machine, which is called Server. The Server side controls the content of the information and the Client side defines the graphic representation of it. In simplest configuration of two-tier architecture could be no Application layer and communication between Client and Data base is performed directly.
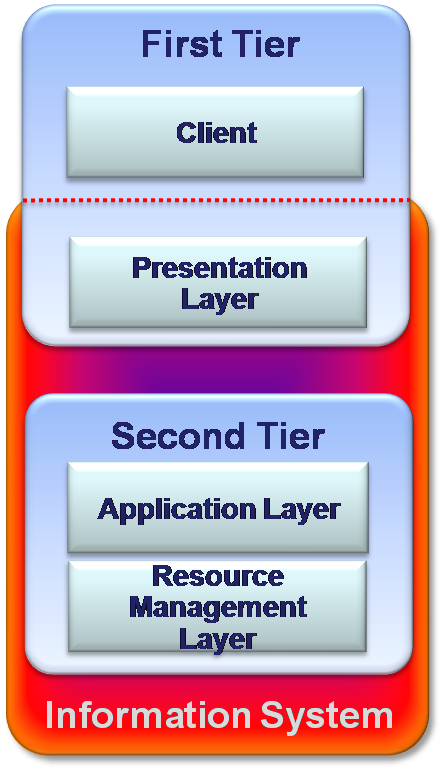
The two-tier architecture has the advantage of running clients – independent programs simultaneously which can be customized according to the requirements of the users. There is improved scalability as it can accommodate up to 100 users concurrently. Two-tier architecture has an improved flexibility by allowing data to be shared, usually within a homogeneous environment. There is improved usability which makes it easier to provide a customized user system interface, which means that every Client/user can get from the system his own interface.
The system enables the Clients to perform sizeable amount of functionality, sharing computations with server and saving server’s resources and processing time and it presents more clear logical and physical separation between data and its presentation. There is significant improvement of UI presentation as a result many client actions can be performed without communicating with the server. The server side is still toughly coupled, which makes it easier for development and management from the software engineering aspect and the system still keeps good performances.
Since the server has to deal with clients’ connections, the number of possible clients is restricted by the server and its capability of managing concurrent connections is made limited. The scalability (100 concurrent users) does not fit in with the requirement for public Internet systems with thousands or even more concurrent users. Clients are very sensitive to even minor systems changes. For example, once a connection configuration has been changed, all existing Clients have to be updated or replaced. According to (Alonso & Pautasso, 2006), “There is no failure or load encapsulation. If the server fails, nobody can work. Similarly, the load created by a client will directly affect the work of others since they are all competing for the same resources.”
If clients want to access two or more servers, 2-tier architecture causes several problems:
- The underlying systems do not know about each other.
- There is no common business logic.
- The client is the point of integration (increasingly fat clients).
- The responsibility of dealing with heterogeneous systems is shifted to the client.
- The client becomes responsible for knowing where things are, how to get to them, and how to ensure consistency.
- This is tremendously inefficient from all points of view (software design, portability, code reuse, performance since the client capacity is limited, etc.).”
“Two tier architectures can be difficult to administer and maintain because when applications reside on the client, every upgrade must be delivered, installed, and tested on each client. The typical lack of uniformity in the client configurations and lack of control over subsequent configuration changes increase administrative workload” (Sadoski, 1997).
Three-Tier: Middleware and distributed systems
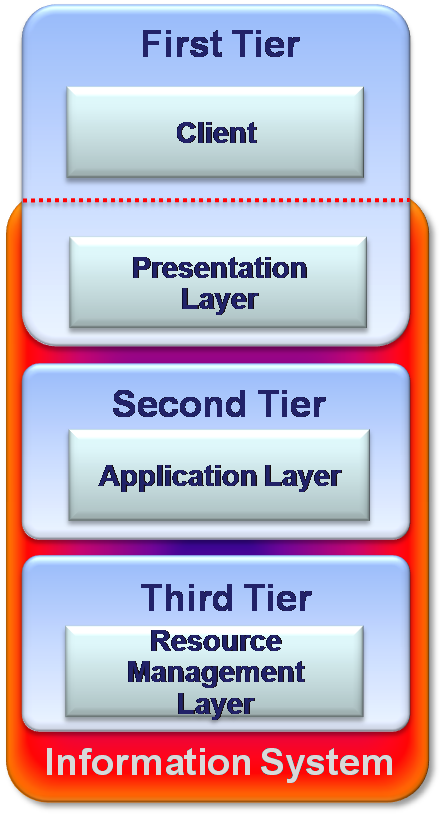
The three-tier software architecture emerged in the 1990s to improve the two-tier capabilities and overcome its limitations. Especially this architecture became popular for Internet applications and net-centric information systems. As opposed to 2-Tiers architecture where the server side is centralized, in the 3-Tiers model the server side separated into two tiers. In addition to 2-tier’s server tier, there is a “Middleware” tier placed between Client and Server. This tier makes indirection between the client and the underlying layers of the system.
The three-tier architecture reduces the number of interfaces between client and server and thereby improves scalability by accommodating hundreds of users, through providing functions such as queuing, application execution, and database staging. It improves flexibility as the system’s components can be easily added or moved. Three-tier architecture improves security as this architecture makes it possible to give to the different parts of the system various security restrictions. There is high level of availability since even when a part of the system crashes down, it does not prevent from users to keep using the system. (Computer cluster technology is widely used to assure high availability).
The other advantages are; Load balancing – tiers make it possible to share loading stresses between different machines. (NLB – Network Load Balancing); creates abstraction above the underlying system – transparent access. Clients see only the middleware as the whole system; exempts the client from locating resources – like Data base connections; manages, locates resources and gathers results from underlying layers or systems; creates higher level of the system’s modularity; facilitates integration of legacy systems.
“Three tier architectures facilitate software development because each tier can be built and executed on a separate platform, thus making it easier to organize the implementation. Also, three tier architectures readily allow different tiers to be developed in different languages, such as a graphical user interface language or light internet clients (HTML, applets) for the top tier; C, C++, C#, Visual Basic, Java for the middle tier; and SQL for much of the database tier” (Sadoski, 1997).
The three-tier architecture has several disadvantages also. The system becomes much more complex and performance hits may occur while transmitting data between tiers (For example: network connectivity). There is the need to get middle tier standardized. It is not always obvious how to separate the system’s functionality into three tiers. Some logic management may appear in all three tiers. There is ddifficulty and cost of system design and development and it possesses ddifficult deployment and maintenance.
N-Tier
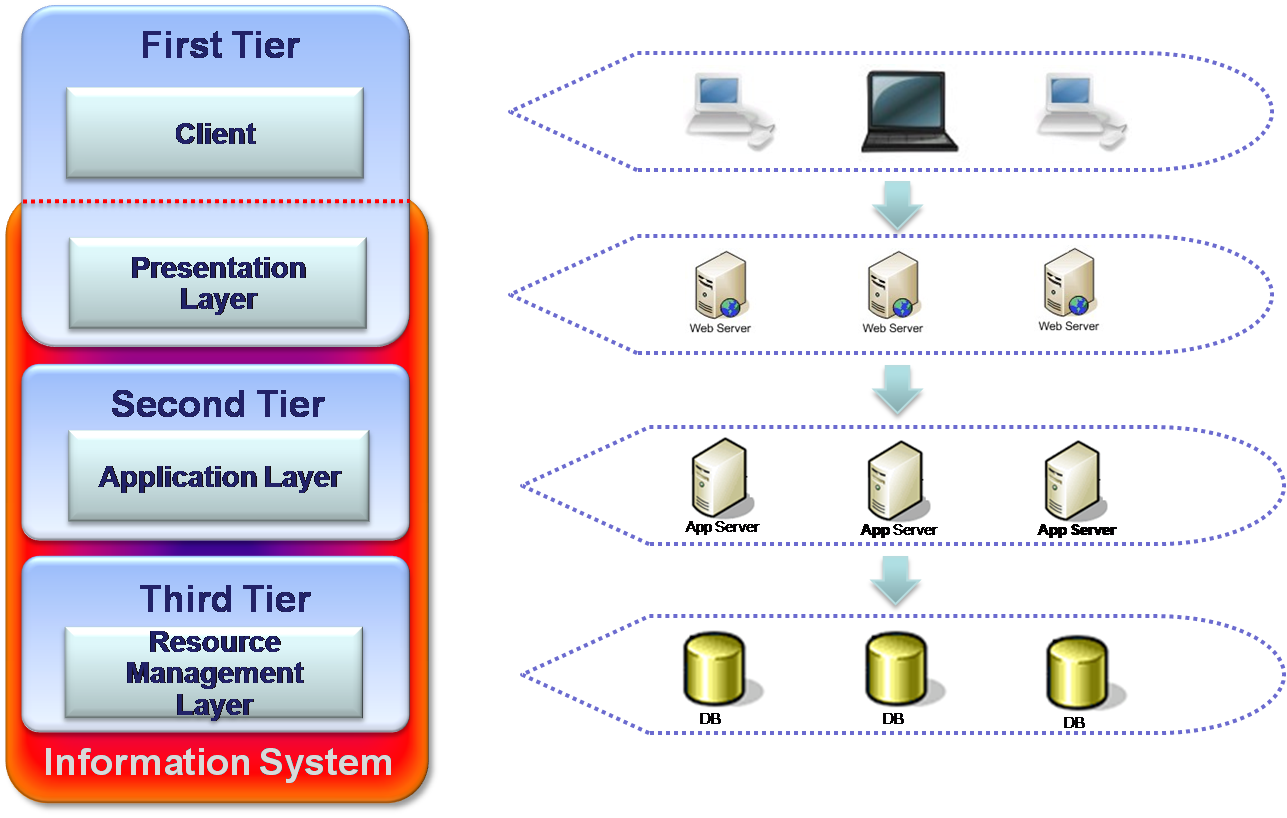
Though there are no physical limitations for dividing any system into different tiers, system architectures should always remember that introducing of an additional tier (not a layer) might be very expensive, especially when performance is been taking in the consideration. It is in the order of 1000 times slower to make remote actions between tiers (across different machines) than to make them within the same machine.
In practice, supplementation of a new tier is a result that caused by different constraints. For example, usually the most significant part of any Information system is its data; therefore, very often the system’s database must be running on the Cluster server or few servers. Cluster technology products license is very expensive; therefore excluding some system’s components out of the Cluster can reduce costs. Let us look at imaginary hard working Information system, which in addition to all its heavy jobs has to derive reports.
These operations can influence database performance. Therefore, one way to resolve that performance issue is to add one more database server, which will replicate the main DB server and will be used for reports deriving only; of course, also this additional server must be running on Cluster and this is going to increase costs. Another way to deal with this problem is to create additional tier, which will be dedicated to process reports instead of the database. This tier can contain few independent machines that have no need to run on Cluster – the result is cost reduction.
David Hayden sums it up as “Tiers are not a good thing; they are a necessary evil required to obtain certain levels of scalability, fault tolerance or security. Layers are a good thing in that they provide highly cohesive, loosely coupled areas of interest that can help increase maintainability of your application. However, over-architecting your application by providing high degrees of loose coupling between layers when unnecessary can be just as harmful to performance and the complexity of an application as tiers. Practice Test-Driven Development and Refactoring to Patterns to keeps things simple now and provide extensibility on demand later when new requirements pop-up.” (Hayden, 2005)
Design Methods
A design is defined as the bridge between software requirements and an implementation, which satisfies the software requirements. The main purpose of design is to determine how the system will work. While arriving at the designs the first step is to determine the overall architecture of the system. It is also necessary to work out the tradeoffs between reliability, generality, portability, and user friendliness.
This implies that the design should be capable of meeting the software requirements with ease, speed and accuracy. There are several steps involved in the design process. These are;
- developing a conceptual view of the system,
- establishing the system structure,
- identifying the data streams and data stores,
- decomposing high level functions in to sub-functions
- establishing relationships and interconnections among components,
- developing concrete data representations, and
- specifying algorithm details (Design, 2005).
There are different methods adopted in designing the software requirements
Top-Down Design
In this method, attention is focused on the global aspects of the overall system requirements. As a next step, the system is decomposed into subsystems and focus is drawn to more specific issues involved. Backtracking is fundamental to any top-down design. In general, the top-down design is based on stepwise refinement of the abstract functions of the system. In a top-down approach refinement of the functions may be described as the development of a tree where the nodes represent elements of the decomposition. Top-down design can also show the control structures more efficiently.
A top-down design method is a method in which analyst “starts with the big picture and works down to the details”. It usually created to run in homogenous environments in which way of distribution has to be specified. This method divides the system among several components. Each component’s functionality depends on other components, and no single component is standalone.
The top-down design contains four steps as shown in the diagram below:
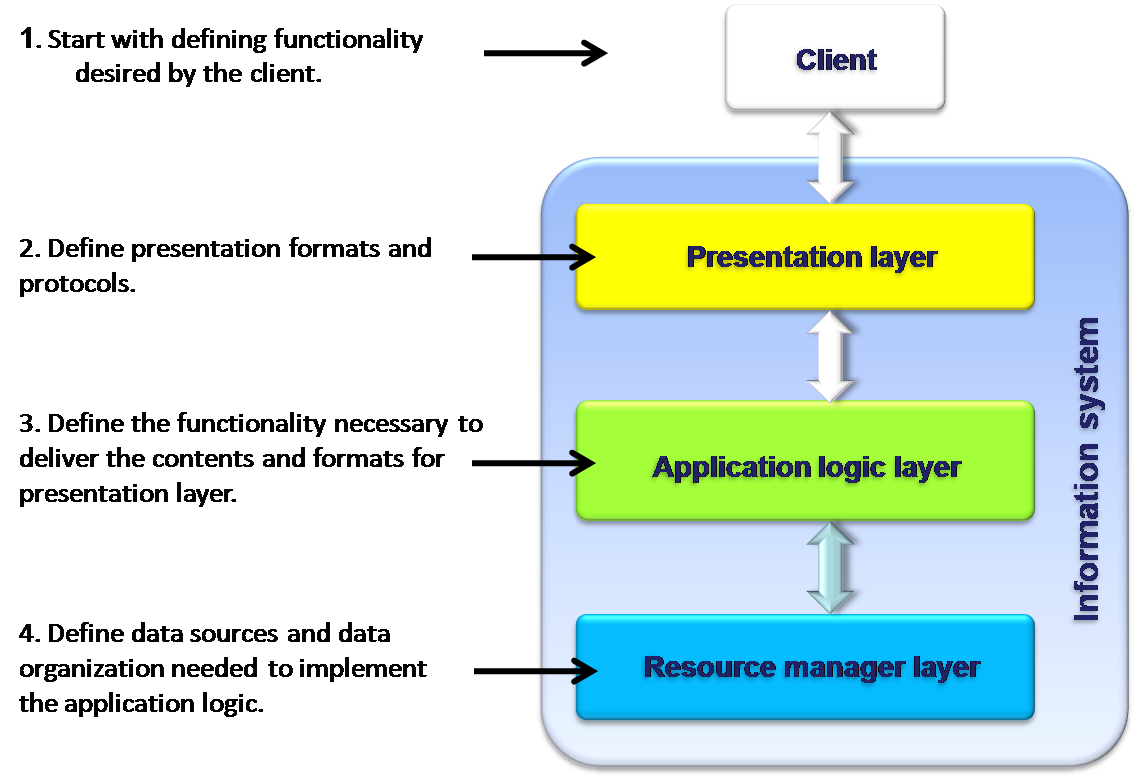
Top-down design method has the specific advantage of focusing on the final goal of the system. The design can be optimized for functional and non-functional (performance, availability) issues. This method also reduces the impact of changes that come late in the design cycle. However, the method suffers from the drawback that it can only be designed from the very beginning. There should be a clear and elaborate definition of the requirements and there will be no possibility of integrating the legacy systems. Due to this inherent drawbacks currently, only few Information Systems are designed purely top-down.
Bottom-Up Approach
In the bottom-up approach a set of primitive objects, actions and relationships that form the basis of the problem solution are identified. The next step is the formulation of higher-level concepts in terms of the primitives. The success of bottom-up approach depends largely on the identification of the primitive ideas that will supplement the system effectively (Design, 2005). Bottom-up is a traditional design approach.
The design process starts with design of individual blocks, which are combined to the system. Each block is verified as a standalone unit and not in the context of the overall system. This kind of design usually used out of necessity rather than choice when there is a need to integrate legacy systems. Most of distributed Information Systems are result of a bottom-up design. Web services can make those designs more efficient, cost-effective and simpler to design. The bottom-up design contains four steps as illustrated in the diagram.
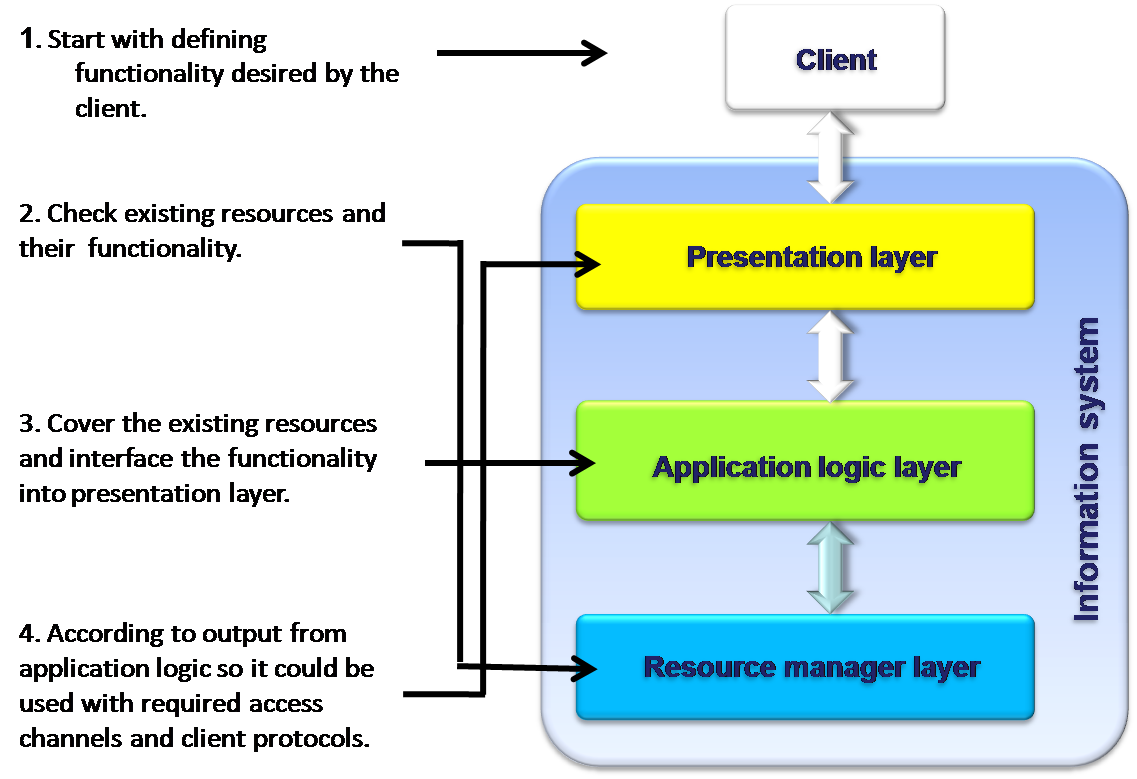
This design method is mostly preferred as it gives the designers the maximum scope for designing creative ideas. However, there is the need that the whole picture of the system is to be decided in advance at the beginning of the project, which may be found difficult under certain circumstances. Another drawback with the system is that during block combination, simulation and verification are difficult and sometimes impossible. Sometimes fixing a problem is expensive because it involves redesign of the entire system.
It is observed, that both the designs methods have both advantages and disadvantages. This makes the use of any particular design method expensive and cumbersome. Therefore, in order to derive the best advantage designers normally adopt a system design, which is a hybrid of both the methods because they are compatible.
Summary
This chapter detailed the evolution of the multi-tier architecture for designing information management systems. A review of the related literature revealed that the development of multi-tier architecture took place along with the development of program languages. The chapter also detailed the information on single, two, three and multi-tier architecture in addition to the advantages and disadvantages of those architectures. A brief outline of the different design methods was also presented in the chapter.
Research Methodology
The objective of this chapter is to present a brief outline of the research method employed to complete the study. The study adopted a secondary research method to collect and present detailed description on the multi-tier architecture and their use in information management systems. Interviews were conducted as a part of the study to obtain expert views on the technicalities of the information management system designs. Case studies of two different information management systems as they are being adopted by few companies in Israel are also presented in this chapter.
Introduction
In general, there are different research methods that are being used to conduct research under social science. The methods are intended to enhance the knowledge and understanding in different areas of social science. There are many ways of classifying the research methods. However, the most popularly used distinction is between qualitative and quantitative research methods. The different types of quantitative and qualitative research methods are linked to epistemological and theoretical frameworks. The research methods are usually classified under five common categories. They are;
- experimental,
- correlation,
- natural observation,
- survey and
- case study.
It is necessary to find and adopt a suitable research method for conducting of any research in the realm of social sciences. The choice of the particular research method depends on the nature and topic under study and the aims and objectives of the research.
Qualitative Research Methods
Qualitative research methods facilitate an in-depth study of social and cultural phenomena of the subject being researched upon. Qualitative research method employs several research techniques like case studies, action research, structured interviews and ethnography. According to Creswell (1994) qualitative research adopts a process of enquiry that goes in-depth into the understanding of all issues connected with the social or human behavior with respect to the particular subject being studied. Creswell (1994) observes that the process of qualitative research considers the views and perceptions of informants who are chosen as the participants to the study.
In the qualitative research, the views and opinions of these informants are observed in a natural setting and reported. Qualitative research usually engages several data sources for supplementing the research. These data collection methods include observation and participant observation (fieldwork), structured and semi structured interviews, focus groups and questionnaires, documents and texts. Sometimes the researcher himself/herself adds to the knowledge by incorporating his/her own impressions and reactions on the subject being studied.
Techniques for Data Collection
Each of the research method adopted uses one of more techniques for the collection of the required empirical data. The word ‘empirical materials’ is considered more appropriated by the qualitative researchers as most of the qualitative data is non-numeric. The techniques adopted for collection of empirical materials range from interviews, focus groups, observational techniques including participant observation and fieldwork. The written data is collected from published and unpublished documents, reports, newspaper articles, publications in professional journals and so on.
It is observed as a common practice in anthropology and sociology to distinguish between sources of data as primary and secondary sources. In general primary sources comprise of those data, which the researcher has collected originally from the people or organizations directly and which remain unpublished, while secondary sources of data are represented by any print materials like books, articles etc which have been published previously. (Walliman, (2005) defines the primary sources as the ones that are usually direct and detached wherefrom the information and data is gathered.
Saunders et al, (2003) feel that the secondary data possess greater value since a number of sources are being used for collection of data. However, Walliman (2005) considers the secondary data as having a shortcoming in which the reliability of such data is always questionable. He further states that since the secondary data are passed on through several hands there is the possibility that such data might contain errors that can vitiate the results of the study and disturb the focus and direction of the research. Authors like Denzin & Lincoln, (2005), Miles & Huberman, (1994) Rubin & Rubin, (1995) have contributed a great deal to the qualitative techniques of data collection. Silverman, (1993) and Myers & Newmann, (2007) have evolved definite guidelines for conducting qualitative interviews based on a dramaturgical model.
Review of Secondary Data and Analysis
Secondary research consists of the analysis of information and data gathered previously by other people like researchers, institutions and other non-governmental organizations. The data are usually collected for some other purposes other than one, which is being presently attempted, or it may help both the collection of data for both the studies (Cnossen). When undertaken with proper care and diligence secondary research can prove to be a cost-effective method in gaining better understanding of the specific issue being studied and conducting assessments of issues that do not need collection of primary data. The main advantage of secondary data is that it provides the basis for designing the primary research and often it is possible to compare the results of the primary research with secondary research results (Novak).
Semi-Structured Interviews
Semi-structured interview is the most common form of interviewing technique in which the interviewer has determined the set of questions he/she intends to ask in advance but still allows the interview to flow more conversationally. In order to have the flow of conversation the interviewer can change the order of the questions or the particular wording of the questions. The main objective of the semi-structured interview is to get the interviewee to talk freely and openly so that the researcher would be able to obtain in-depth information on the topic under study.
For collecting expert views and opinions, this study conducted interviews with two software industry experts. Questions on the designing, advantages and disadvantages of multi-tier architecture, their use in the information management systems and the future of the technology in general were put to these experts and the views and ideas expressed form part of this study. Since the interviews took the form of informal chats with the interviewees, no transcripts of the interview questions or the answers are appended to this report.
Case Study
Several research studies have used case study as a research methodology. “Case study is an ideal methodology when a holistic, in-depth investigation is needed” (Feagin et al, 1991). Various investigations particularly in sociological studies have used the case study as a prominent research method to gather pertinent knowledge about the subjects studied. When the case study procedure is followed, the researcher will naturally be following the methods, which were well developed and tested for any kind of investigation.
Case study research cannot be considered as a sampling research. However, the selection of the cases is of crucial importance so that the maximum information can be gathered for completion of the study within the time available. It is a frequent criticism of case study research that the results are not widely applicable in real life. Yin in particular refuted that criticism by presenting a well-constructed explanation of the difference between analytic generalization and statistical generalization “In analytic generalization, previously developed theory is used as a template against which to compare the empirical results of the case study” (Yin, 2002).
Choice of Research Methods for Current Study
In view of the technical nature of the subject, conducting primary research was beyond the scope of the academics. Therefore, the study has adopted secondary research for the collection of data and information for the completion of the research. To supplement the research the study has also used semi-structured interviews with professionals in the field of research along with case studies of information management systems as being practiced by many companies in different business spheres in Israel.
Summary
This chapter presented an overview of the research methods that were adopted for completion of this study. Secondary research combined with semi-structured interviews and case study were the methods used by the study. The findings and analysis of the research are presented in the next chapter.
Findings and Analysis
Through the secondary research, this study identified some “best practices’ of already existing information management systems and this chapter presents these systems as case studies. These systems are presently being practiced in some of the manufacturing and financial services companies in Israel. As a part of this research, interviews were conducted with some of the industry specialists whose views are also included in the presentation. In view of anonymity and confidentiality and the copyright requirements, the name of the companies or the specialists are disclosed
Introduction
The current study on the development and use of multi-tier architecture is supplemented by studying the information management systems already developed and in use in some of the companies for applications in different domains. The review of the related literature provided the basic knowledge on the subject matter. The case studies will add to this existing knowledge by elaborating the functional aspects of the use of multi-tier architecture in practical environments. The advantages and disadvantages of the different systems are also discussed which are relevant from an academic point of view.
The semi-structured interviews conducted with the industry professionals has lead to a detailed discussion on the various other aspects of the information management systems and the future of multi-tier architecture systems in the field of information and communication technology. Several educational, scientific, commercial and military applications have been developed using the multi-tier architecture technology. Further developments in the field try to remove the barriers and bottlenecks found in the current systems and usages.
Funds Management System
This Information system is for managing Funds (like Pension, Study and the like) has been developed by one of the largest Israeli IT companies for one of the Israeli banks. The purpose of this system is to manage funds accounts, including deposits, debts, employer, employees and others. This system runs in bank’s LAN environment and serves dozens of concurrent users. The system is based on Microsoft solutions as Windows Server,.Net and MSSQL. It is built according to Microsoft 3-tier architecture model. The diagram below illustrates the structure of the architecture and the layers involved in the architecture.
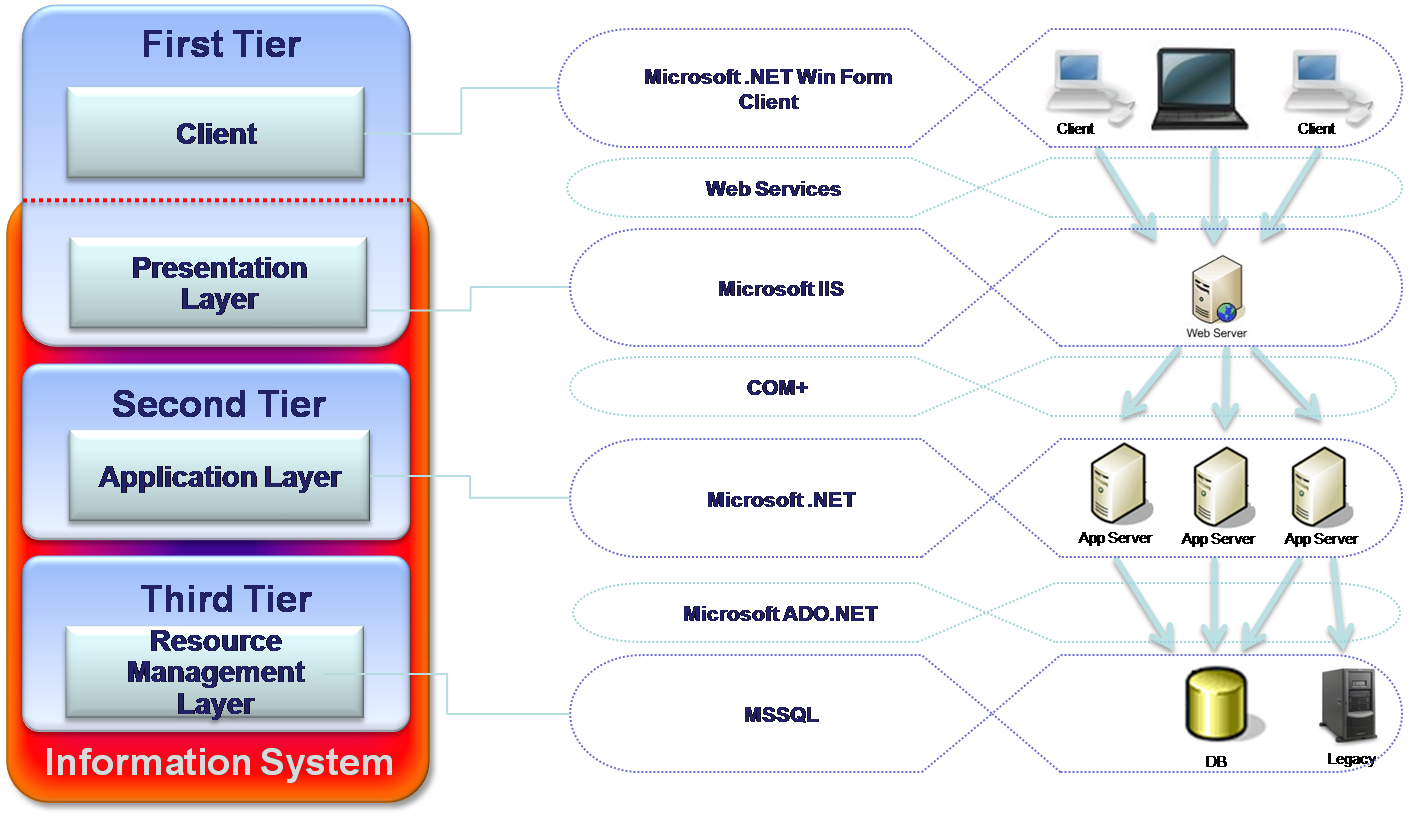
The analysis of the architecture reveals that this structure is direct result of what roles were given to each part of the system. One of the very important steps in system design is to decide which part of the system is going to deal with the business logic. For example, whether the business processes are going to run – whether on the database server or should be taken out to the application server. In this particular system, the business logic was taken out of the database to the application server – so we have two layers: Data Source and Application. For performance and security purposes the application layer was taken out to separate tier contained of few machines – so we have two separate tires (see figure 9).
Clients can converse with the server side through the Web server. So on one hand we could place Web server on each application tier computer, but it would cause unnecessary redundancy, deployment issues, additional expenses and the most important thing is that the Clients have to decide which of those Web servers they need to call. There is no way but introduce additional tier that will store the Web server. Therefore, there are three separate tiers involved. The Clients will communicate with the Web server and the Web server will act as an orchestrator, routing the requests to the right application server (see figure 9). The system is supposed to serve dozens of concurrent users; therefore, one Web server is quite enough to withstand the load.
The main advantage of this system is the scalability. It is possible to broaden the system easily. For example, if the number of the concurrent users exceeds 100, there will be no problem to add many more Web servers as needed. Flexibility is another advantage where the system can be used to serve other bank customers. It can be achieved by replacing application modules components, fitting them to the new customer.
The architecture has also the advantage of easy maintainability since every application server runs one or few business modules this makes it possible to partially deploy the system. This implies that the customer can use the system before all its modules complete. It makes the maintenance easier and facilitates the QA (Quality Assurance) process.
Nevertheless, the system has also some disadvantages. The system has a limitation on its performance. The development business logic used upon few Application servers requires management of distributed transactions in order to prevent failures, which may cause incorrectness of the DB data. In this project, it has been done using the COM+ technology, which causes in many cases performance hits. The deployment is quite complicated, including the following installations: Client programs, Web server, few Application servers and the database. Maintenance also becomes complicated and expensive since variety of the servers and supporting technologies requires thoroughly professional employees. However, the advantages overweigh the disadvantages, which make the use of system more popular.
Retail Management System
A largest software company in the retail domain has developed this Information system. The system is intended to help the middle management layer of retail companies, like supermarket or convenience stores chains. It makes it possible to manage stores activities from the headquarters. Using this system, managers can define products catalogs, prices, suppliers, promotions and other necessary usages. The diagram appended below illustrates the architectural design (See fig).
In contrast to the Funds management system, the Retail management system’s logic is concentrated in the Resource Management layer or in other words in database objects (stored procedures, functions, jobs, and triggers). Therefore, the Application layer is merged with the Presentation layer. Both layers are located in the same tier containing few Web servers. The number of the Web servers is defined per customer, according to the number of concurrent users. Load Balancing or NLB technologies spread loads between the servers avoiding overloading stresses. Application layer has a role of a router, directing the users’ requests to the right database server.
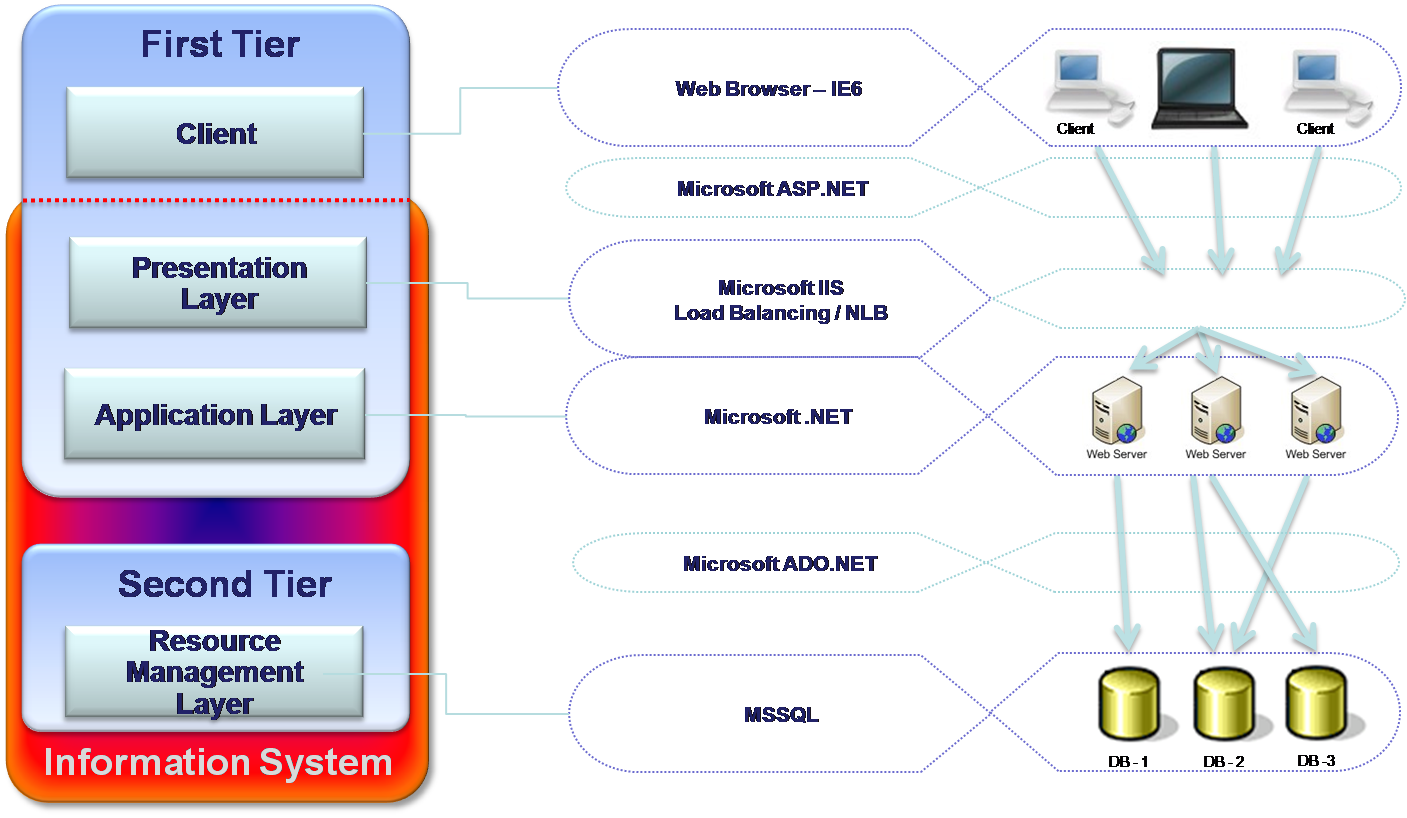
The retail information management system carries several advantages. On the area of performance, there is a definite improvement since the system performs most of the business logic on the DB, which usually achieves performance improvement. The deployment of this system is much easier as compared to the Funds management system, since the system deploys only Web and database servers. The scalability is also high because of the Load Balancing or NLB technologies. In some cases, it also becomes a disadvantage.
The system suffers from certain disadvantages. The development proves to be highly difficult because of the modularity lack in the database objects. As far as maintenance is concerned, it is considered difficult, as the database, code is very difficult for bugs searching. Though the scalability is high and is very easy to deal with growing amount of user on Presentation layer (see advantages – adding Web servers), it also can cause a very serious problem by overloading the database.
The reason of possible overloading is the fact that the business logic runs on the DB. The system is very expensive because in that kind of architectures, in order to increase the number of concurrent user, the customer should add more database servers or improve existent. This may dramatically increase the system’s expenses. This structure cannot assure high availability and the moment the database failed, the whole system is down. The flexibility is also found to be low as no abstraction is possible above the DB, the data and the logic is in the same place.
Discussion and Analysis
Certainly, there is no absolute answer to the question – what is the best system architecture? Every time a system architect begins a new information system design, he should refer to a number of aspects and constraints affecting the design and architecture. The main goal of the system design and development should be the achievement of the required functionality – the system should be able to perform all the actions that it was planned.
It is very important for every information system to meet the basic requirement of the usability, scalability, flexibility, maintainability, reusability, security, fault tolerance, complexity and performance. Often there is no way to keep all of these together; many times, there is a tradeoff between the scalability and high availability on one side and the performance on another. The number of the concurrent users and its raise play a very significant role while designing a new system. Sometimes it’s better to increase scalability by broadening “up” – adding of hardware to the existing servers, instead of broadening “out” – adding of new servers and creating additional tiers.
The decision about the location of the business logic implementation may have very significant influence on the systems structure. Some systems have very complex business logic algorithms, which consume sizeable amount of computer resources. In that kind of systems, it is very acceptable to take the business logic functionality out to separate application server or few servers, creating by that an additional tier. This move on one hand comes to resolve the problem of performance hits, but on the other hand, it may cause much more headache in aspects of the communication, development and maintenance complexity, data consistency and even more serious performance problems. Each of these aspects is discussed in the following sections.
Communication
It is quite clear that separating a process into two independent machines requires a highly available communication channel between them. Communication problems happen because of many reasons, like connection problems, and security settings. Despite the fact that these kinds of problems can be solved by the system administrators and never come back, these issues still have to be taken in the consideration of ensuring high availability of the systems.
Development and maintenance complexity
Addition of new tiers causes to developers to face various issues, which require from them experience in few other technological spheres.
The following table contains the most important criterions (columns) and few characteristic Information systems. Every system type graded for each criterion according to the research we have made. The grades are in range of 1 – 10 and have no influence on each other.
Table 1: Importance of criterions for few characteristic Information systems.
Internet portal
Means a public available system, like Walla, and Yahoo. In that kind of systems the number of concurrent users is growing permanently, that is why the scalability issue is highly important. The content of these systems is very dynamic and often requires additional components to supply the needed functionality; therefore the flexibility issue is also plays a significant role. For the same reasons, but with less importance the maintainability issue has to be taken in the consideration. The High availability is also very important, but no critical – if for some reason the portal is not available for few minutes, nobody is suffering.
In order to achieve scalability and flexibility the system can be easily broaden by adding new tiers. In spite of performance hits, the main criterions play more significant role.
Customer service
This kind of Information system can be used by customer agent or Internet bank site. Such system cannot be unavailable even for a very short time. Of course, the security issue is high priority, protecting customers’ personal information. Leakage of that kind of information may cause undesired results, like law procedures.
These most important criterions (high availability and security) can be achieved by adding new tiers and layers, with no importance for performance.
Military/Medical
This kind of Information system can be used by medical personal and military staff. Usually these systems require best performance and high availability because they are responsible for humans’ lives. Faults of any kind are unacceptable while dealing with vital operations. Even if any fault occurs, the system must not crash or deny any service. Therefore, the fault tolerance is one of the most important criterions while designing such kind of a system. Because of these reasons, the Maintainability plays very significant role while overcoming on system’s faults. The last but not the least is the security issue to assure privacy and confidence for the institutions that use those systems.
This is the classic case when the tradeoff between the scalability and high availability on one side and the performance on another has to be resolved. Performance requires reducing amount of tiers, but for security and High Availability issues it is almost necessary to increase their number.
Report Generator
This can be a subsystem of any operational system or independent system. Usually that kind of system does not require high level of performance or availability. Many times users activate reporting services not during peak hours, therefore performance has low importance. Usually reports amount grows up all the time that is the reason for high scalability requirement.
In opposite to the previous system type, in this case increase of tiers will be invited. This can easily resolve the scalability issues. The only limit for tiers increase should be the system’s complexity.
Future of Multi-Tier Architecture
There are several developments taking place to remove the drawbacks in the traditional single, two and three tier architectures. Some of which are discussed in this section. A modified 2-tier model is an answer to improve the reusability of business logic. Here the approach is to place the logic into triggers or stored procedures on the database. By adopting suitable database stored procedure, it is easy to perform validations. It is also possible to initiate dependent logic by a trigger in the database. This approach has the advantage of better re-use in which the same logic stored in procedures and triggers can be initiated by a number of client applications and tools. The system provides better data integrity when the validation logic is initiated in database triggers unconditionally. This way the integrity of business data is ensured.
The system is found to be working satisfactorily and showing improved performance in situations of complex validations. This implies that “when the business logic requires many accesses back-and-forth to the database to perform its processing, network traffic is significantly reduced when the entire validation is encapsulated in a stored procedure”. Stored procedures are capable of improving security as there is the provision for encapsulation of detailed business logic in a more secure and central server. One other advantage with the system is that databases only are to be updated with the changes in business logic and there is no need to distribute the logic to all the clients.
Despite the advantages, the modified 2-tier approach still suffers from the inherent drawbacks of the traditional 2-tier approach, though it addresses some of the concerns of the traditional model. The most noted drawback is the continued scalability, which was taken care of by the 3-tier model. However, the complexity concerns of the traditional 3-tier model cannot be easily ruled out. In many situations, it becomes essential to incorporate the benefits of the 3-tier model.
For instance in situations like where a small number of users maintain the bulk of the data; it is necessary to support a large number of users; it is necessary that some information/data need to be exchanges with other applications with the current application and the requirements of some of the users to get direct access to the data for the purpose of using some special tools are to be met a hybrid 2-tier/3-tier model may be of use (See fig).
In this situation, the bulk of the users would make use of the internet clients and/or simple client/server front ends to access data though application server. In this case, access through the application server provides the benefits of scalability. Moreover, application servers would facilitate the exchange of related applications so that there can be an efficient management of interface between them (Woodger Computing Inc, n.d.).
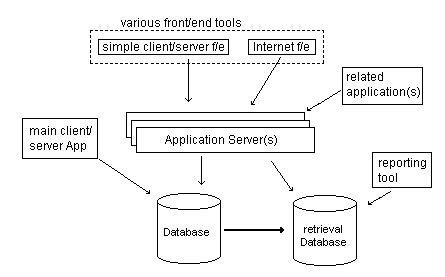
In this hybrid model, the bulk of the logic would be built using a traditional 2-tier model. This facilitates the productivity optimizations of many client/server tools and it is easier to manage and co-ordinate the development of 2-tier architecture. One of the distinguishing features of the hybrid model is the inclusion of a replicated database. By including, the replicated database, which is optimized for retrieval the model, satisfied certain special requests from application servers. The retrieval database also enables the users to access data with special reporting tools (Woodger Computing Inc, n.d.)
Summary
This chapter presented the case studies of multi-tier information management systems, which are used in various business domains in Israeli companies to enable the understanding the role and functions of the multi-tier architecture. The chapter also discussed some variants of the 2-tier and 3-tier architecture, which are the findings from a secondary research
Conclusion and Recommendation
Conclusion
Irrespective of the creativity and cleverness applied in the design, development, and operation of information management systems, the fact remains that the information management system still represents a repository or storage facility created to store and retrieve data for various business and other purposes. Therefore, the value of the information management system depends entirely upon the analytical ability of the applications, which access, process and presents the data, information and knowledge used to support the analysis of the data stored and problem-solving requirements of the users.
Data Mining capabilities are central to the utility of any information management system. Top-level applications tend to perform with the execution of simple queries with options derived from the basic metadata model. At the same time, advanced searches will provide for increased complexity. This will allow the users to go in-depth into the information management system to get the desired data and information processed and output obtained in the desired format. Advanced searches also enable users to create queries that include analytic and computational tests. Therefore, in order to meet these requirements the architecture should be designed in such a way it meets all the requirements of the users and their applications.
Recommendations
This research has identified potential areas of further research in workflow applications, new software development technologies that will extend the existing knowledge on the field of information management system.
References
Alonso, G. & Pautasso, C., 2006. Multi-Tier Organization of an Information System. Swiss Federal Institute of Technology: IKS Information and Communication Systems Research Group.
Cnossen, C., 1997. Secondary Reserach: Learning Paper 7, School of Public Administration and Law, the Robert Gordon University. Web.
Creswel, J., 1994. Research Design: Quantitative & Qualitative Approaches. Thousands Oak: Sage Publications.
Denzin, N.K. & Lincoln, Y.S., 2005. The Sage Handbook of Qualitative Research. Thousand Oaks: Sage.
Design, 2005. Design Process. Web.
Feagin, J., Orum, A. & Sjoberg, G., 1991. A case for Case study. Chapel Hill N C: University of North Carolina Press.
Hayden, D., 2005. Web Applications N-Tier vs N-Layer – Benefits and Trade-off. Web.
Horsburg.com, 2000. Data Warehousing (Detail). Web.
MicrosoftCorporation, 2008. Designing Multi-Tier IIS Applicaitons. Web.
Miles, M.B. & Huberman, A.M., 1994. Qualitative Data Analysis: An Expanded Sourcebook, 2nd ed.,. New Bury Park CA: Sage Publications.
Myers, M.D. & Newmann, M., 2007. The qualitative interview in IS research: Examining the craft. Information and Organization, 17(1), p. 627-652.
Novak, P.T., 1996. Secondary Data Analysis Lecture Notes. Marketing Research, Vanderbilt. Web.
Rubin, H. & Rubin, I., 1995. Qualitative interviewing : the art of hearing data. San Diego: Sage Publications.
Sadoski, D., 1997. Client/Server Software Architectures. Web.
Saunders, M., Lewis, P. & Thornhill, A., 2003. Research Methods for Business Students. London: Prentice Hall.
Silverman, D., 1993. Interpreting Qualitative Data. London: Sage Publications.
Walliman, N., 2005. Your Research Project, A step by step guide for first time researcher. 2nd edition. London: Sage Publications.
Wikipedia, n.d. Layer. Web.
WoodgerComputingInc, n.d. Multi-Tier Architectures. Web.
Yin, R., 2002. Case Study Research Design and Method. London: Sage Publications.